Leggera indroduzione alla Complessità computazionale
Indice
Introduzione
La complessità computazionale è una metrica che misura le prestazioni di algoritmi mentre sono sotto grandi carichi di dati.
Ogni applicazione può essere modellata come un sistema che prende dei dati in input e, in corrispondenza di questo input, produce un output. Naturalmente il calcolo dell'output richiederà del tempo che aumenterà all'aumentare delle dimensioni dell'input. La complessità computazionale studia come cresce il tempo di calcolo rispetto alla crescita dell'input.
Consideriamo due algoritmi A e B che sono funzionalmente equivalenti (cioè producono lo stasso output a parità di input) ma diversi nell'implementazione. Ad esempio potrebbero essere algoritmi di compressione che dato un file (la cui dimensione è variabile) ne producono la versione compressa. Testiamo questi algoritmi ipotetici dandogli in pasto file di varie dimensioni e confrontandone il comportamento. Possiamo immaginare di avere risultati di questo tipo:
| File | Dimensione | Tempo di A | Tempo di B |
| file1.txt | 1MB | 0.5s | 0.1s |
| file2.txt | 2MB | 1.2s | 1.5s |
| file3.txt | 3MB | 1.6s | 3.4s |
| file4.txt | 4MB | 1.9s | 5.6s |
| file5.txt | 5MB | 2.1s | 8.6s |
| file6.txt | 6MB | 2.3s | 10.8 |
| file7.txt | 7MB | 2.4s | 13.7s |
| file8.txt | 8MB | 2.6s | 16.7s |
| file9.txt | 9MB | 2.7s | 19.9s |
| file10.txt | 10MB | 2.8s | 23.1s |
| big_file.txt | 100MB | 5.1s | 460.6s (8 minuti) |
| super_big_file.txt | 1000MB (1GB) | 7.4s | 6907.9s (2 ore) |
big_file.txt e super_big_file.txt che sono esempi di file super grandi.
Naturalmente all'aumentare delle dimensioni dell'input entrambi algoritmi ci mettono più tempo a concludere l'esecuzione, tuttavia l'algoritmo A tende a comportarsi molto meglio di B per file grandi. Ad esempio per un input di 2MB gli algoritmi hanno tempi simili, ma per 3MB B impiega il doppio del tempo di A e salendo a 6MB, B impiega 5 volte il tempo di A! In questo caso si dice che A è più scalabile di B, perchè il suo tempo d'esecuzione cresce più lentamente.
Ma come è possibile che due algoritmi risultino in tempi di calcolo così radicalmente differenti? Vediamo un esempio!
Esempio
Possiamo usare l'esempio dell'ordinamento di un array di numeri interi. Esistono molti modi per ordinare un array, ciascuno dei quali ha un tempo d'esecuzione differente. Proviamo implementando due algoritmi di sort chiamati selection sort e counting sort usando il C:
| 1 | int find_lowest(int *array, int size) |
| 2 | { |
| 3 | int min_pos = -1; |
| 4 | for (int i = 0; i < size; ++i) |
| 5 | if (min_pos < 0 || array[i] < array[min_pos]) |
| 6 | min_pos = i; |
| 7 | |
| 8 | return min_pos; |
| 9 | } |
| 10 | |
| 11 | void swap(int *a, int *b) |
| 12 | { |
| 13 | int t = *a; |
| 14 | *a = *b; |
| 15 | *b = t; |
| 16 | } |
| 17 | |
| 18 | void selection_sort(int *array, int size) |
| 19 | { |
| 20 | for (int i = 0; i < size; ++i) { |
| 21 | |
| 22 | // Trova l'elemento più piccolo nella |
| 23 | // seconda metà dell'array, cioè quella |
| 24 | // ancora non ordinata che va dall'indice |
| 25 | // [i] fino a [size-1]. |
| 26 | int min_pos = find_lowest(array + i, size - i); |
| 27 | |
| 28 | // Rendiamo l'indice dell'elemento relativo |
| 29 | // all'intero array e non solo alla parte non |
| 30 | // ancora ordinata. |
| 31 | min_pos += i; |
| 32 | |
| 33 | // Metti l'elemento trovato nella ragione |
| 34 | // ordinata dell'array. |
| 35 | swap(array + i, array + min_pos); |
| 36 | } |
| 37 | } |
| 38 | |
| 39 | void counting_sort(int *array, int size, int min_value, int max_value) |
| 40 | { |
| 41 | int counter_count = (max_value - min_value + 1); |
| 42 | |
| 43 | int counters[32]; |
| 44 | |
| 45 | for (int i = 0; i < counter_count; ++i) |
| 46 | counters[i] = 0; |
| 47 | |
| 48 | for (int i = 0; i < size; ++i) { |
| 49 | int value = array[i]; |
| 50 | counters[value - min_value]++; |
| 51 | } |
| 52 | |
| 53 | for (int i = 0, w = 0; i < counter_count; ++i) |
| 54 | for (int j = 0; j < counters[i]; ++j) |
| 55 | array[w++] = i + min_value; |
| 56 | } |
Il selection sort itera lungo l'array da ordinare e cerca l'elemento più piccolo. Una volta trovato, lo mette all'inizio dell'array. Successivamente cerca l'elemento più piccolo nel sotto-array che va dalla posizione 1 fino alla fine (per ignorare l'elemento già ordinato) e lo mette alla seconda posizione. Poi trova l'elemento più piccolo nel sotto-array che va dalla posizione 2 sino alla fine e così via, iterando finchè l'array non è ordinato. Il counting sort d'altro canto itera lungo l'array e conta le occorrenze di ciascun numero che incontra. Contati tutti i numeri, costruisce una nuova versione dell'array che ripete gli elementi tante volte quanti ne ha contati, in un colpo solo!
Questa tabella contiene i risultati. Ho aggiunto la funzione di sorting della libreria standard C qsort per avere un riferimento.
| Numero di elementi | Selection sort | Counting sort | "qsort" |
| 10 | 0.000001s | 0.000001s | 0.000001s |
| 100 | 0.000014s | 0.000002s | 0.000006s |
| 1,000 | 0.000979s | 0.000005s | 0.000064s |
| 10,000 | 0.093092s | 0.000042s | 0.000696s |
| 100,000 | 9.204805s | 0.000451s | 0.007685s |
| 1,000,000 | 941.154007s | 0.004555s | 0.086156s |
Rappresentando graficamente il comportamento di questi algoritmi, si ottiene il seguente grafico (Le due immagini rappresentano gli stessi dati su intervalli diversi)
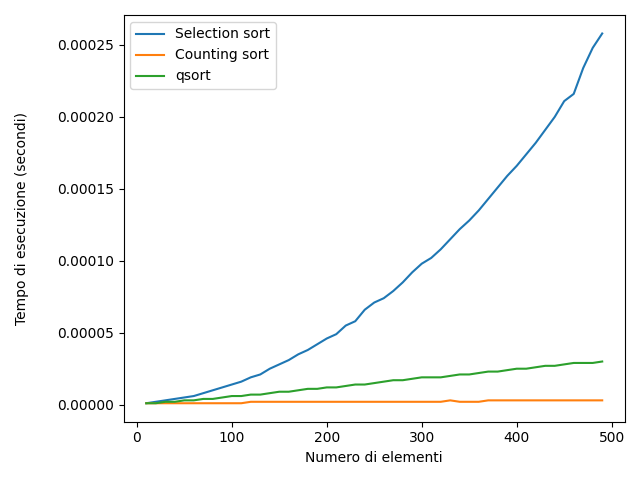
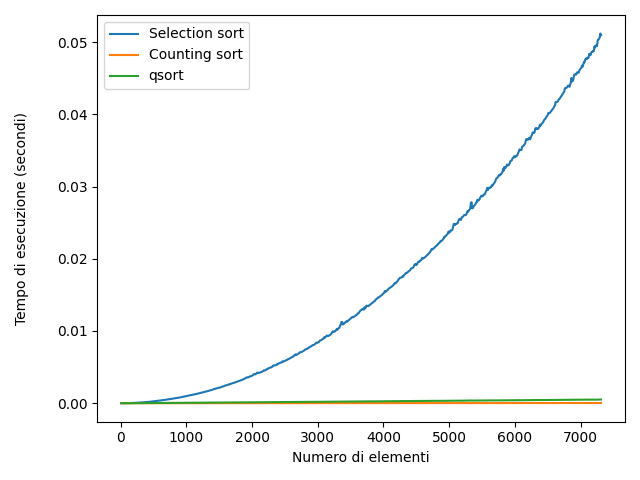
Il grafico relativo al selection sort ha l'andamento di una parabola, mentre quello del counting sort e del qsort sono più simili a delle rette. Questa cosa è dovuta al fatto che, approssimativamente, il selection sort per ordinare un array di N elementi, deve effettuare N^2 operazioni. Il counting sort invece, approssimativamente 2N.
Il software usato per il benchmark è reperibile qui.
Classi di complessità
Il comportamento di questi tempi di esecuzione in realtà potevamo anche dedurlo dal codice senza fare tutte queste prove. Infatti, se diamo una seconda occhiata al selection sort possiamo osservare che consiste in un'iterazione lungo gli N elementi, e per ciascuno di questi viene chiamata find_lowest, che a sua volta itera lungo gli N elementi. Per questo approssimativamente sono necessari N^2 passaggi per completare l'ordinamento.
| 1 | int find_lowest(int *array, int size) |
| 2 | { |
| 3 | int min_pos = -1; |
| 4 | for (int i = 0; i < size; ++i) |
| 5 | if (min_pos < 0 || array[i] < array[min_pos]) |
| 6 | min_pos = i; |
| 7 | |
| 8 | return min_pos; |
| 9 | } |
| 10 | |
| 11 | void selection_sort(int *array, int size) |
| 12 | { |
| 13 | for (int i = 0; i < size; ++i) { |
| 14 | |
| 15 | int min_pos = find_lowest(array + i, size - i); |
| 16 | |
| 17 | min_pos += i; |
| 18 | |
| 19 | swap(array + i, array + min_pos); |
| 20 | } |
| 21 | } |
In modo analogo potevamo dedurre il comportamento del counting sort a partire dal codice. Il for centrale itera lungo gli N elementi, poi l'ultimo for (assieme al for innestato) itera dinuovo lungo gli N elementi. Per questo le operazioni necessarie ad ordinare sono circa N.
I tre algoritmi si comportano diversamente, tuttavia possiamo osservare che counting sort e qsort sono più simili rispetto al selection sort nel modo in cui il tempo di esecuzione aumenta. In generale, è possibile dividere lo spazio di tutti i possibili algoritmi in dei gruppi sulla base della loro similitudine. Essendo leggermente più formali per allacciarci al gergo che si usa comunemente, questi gruppi di algoritmi sono detti "classi di complessità", e si denotano con la funzione che meglio approssima la loro crescita. Ad esempio, il selection sort sarà un algoritmo che fa parte della classe di complessità quadratica, oppure si può dire che il selection sort è "un O grande di N quadro" e si denota con O(N^2). Analogamente il counting sort è un O(N).
Complessità della memoria
Per convenzione, nello studio degli algoritmi l'attenzione è incentrata sul loro tempo di esecuzione, tuttavia ci sono tante altre caratteristiche importanti. A cosa ci serve un algoritmo super veloce se poi richiede così tanta memoria da non poterlo usare? Naturalmente a niente. In quanto programmatori, il nostro lavoro è quello di costruire software che funziona bene nella sua interezza, e pertanto dobbiamo considerare a monte quali sono le metriche importanti e studiare gli algoritmi in base alle loro performance lungo tutte queste metriche.
In realtà, un esempio di questo principio l'ho nascosto sotto i vostri occhi sin da prima! Qualcuno potrebbe essersi chiesto, ma se il counting sort è meglio del qsort, perchè la libreria standard del C non usa quello? Il motivo è che il counting sort funziona bene solo quando i numeri da ordinare hanno valori contenuti in un intervallo limitato. Per ogni possibile intero che potrebbe essere contenuto nell'array deve mantenere un contatore. Nell'esempio di sopra ho assunto che i valori potessero essere solo contenuti tra 0 e 30, ma in generale una variabile di tipo intero del C può rappresentare 4 miliardi di interi, che renderebbe questo algoritmo completamente inutilizzabile! E per quanto riguarda il qsort? Nulla del genere. L'algoritmo della funzione "qsort" della libreria standard non è fissato dallo standard, per cui non possiamo fare conclusioni sulla sua complessità. Comunque di certo è estremamente più ragionevole rispetto al counting sort. Questo certamente mette in prospettiva il valore di quel guadagno di performance evidenziabile dal diagramma.
Solo una parte della storia
Lo studio della complessità degli algoritmi è uno strumento importante, ma che ci permette di analizzare gli algoritmi solo sotto uno specifico punto di vista. Non è detto che un algoritmo con una classe di complessità migliore di un altro sia sempre meglio. Ad esempio, l'analisi della complessità non ci dice come si comportano gli algoritmi per quantità di dati ridotte e che non crescono molto durante l'esecuzione del programma.
Generalmente gli algoritmi più scalabili hanno delle implementazioni più complicate, per cui meno facili da comprendere e da assicurare che siano corrette. Per questo motivo è molto importante che si individui quali sono le parti di un software che devono scalare e si ottimizzino in particolare quelle usando l'analisi della complessità.